SPOKOJENÝCH KLIENTŮ
AKTIVNÍCH PROJEKTŮ
ANALYZOVANÝCH STRÁNEK
za 7 dníEVIDOVANÝCH ODKAZŮ
Průměrné dosažene chybové skóre za včerejší den je 76 / 100
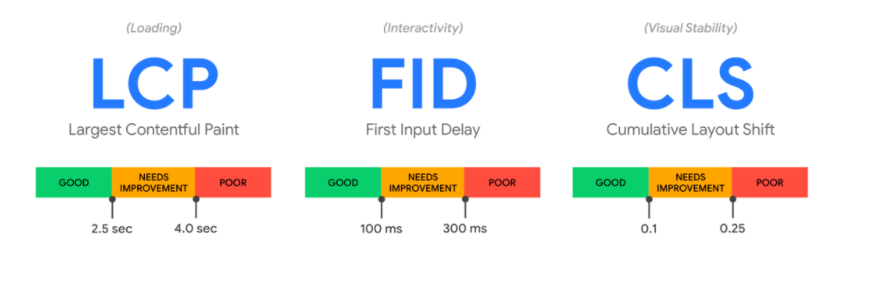
Core Web Vitals
Kontrolujeme 3 základní metriky CLS, FID, LCP. Pro každou máte k dispozici denní grafy rozdělené na mobilní a desktop. Další informace
Kontrola indexace
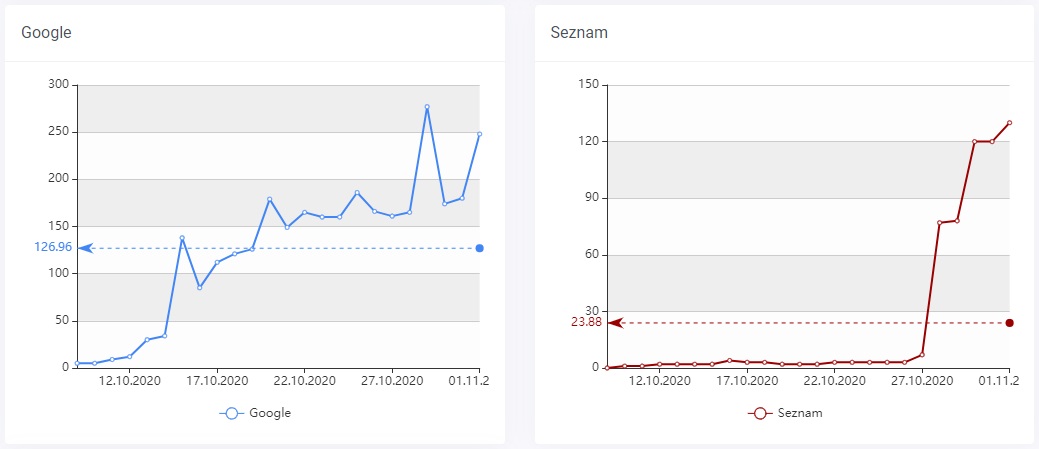
Každý den kontrolujeme počet indexovaných stránek ve vyhledávačích Google a Seznam. Můžete sledovat vývoj indexace, pokud dojde k výraznému poklesu indexovaných stránek (o více než 10%) budeme vás automaticky informovat. Další informace
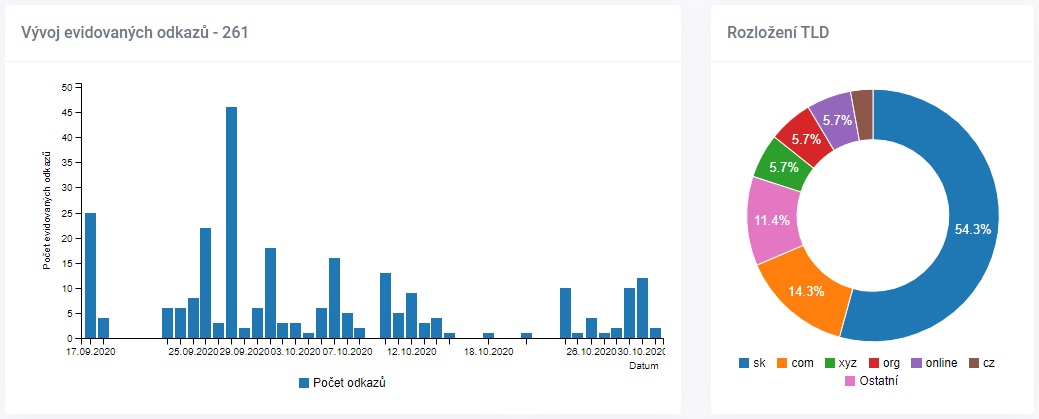
Zpětné odkazy
Každý den kontrolujeme nové odkazy pro váš projekt a ty následně kontrolujeme na funkčnost (jestli nebyly smazány). Nepotřebujete další účet ve službách typu Ahrefs nebo Semrush.
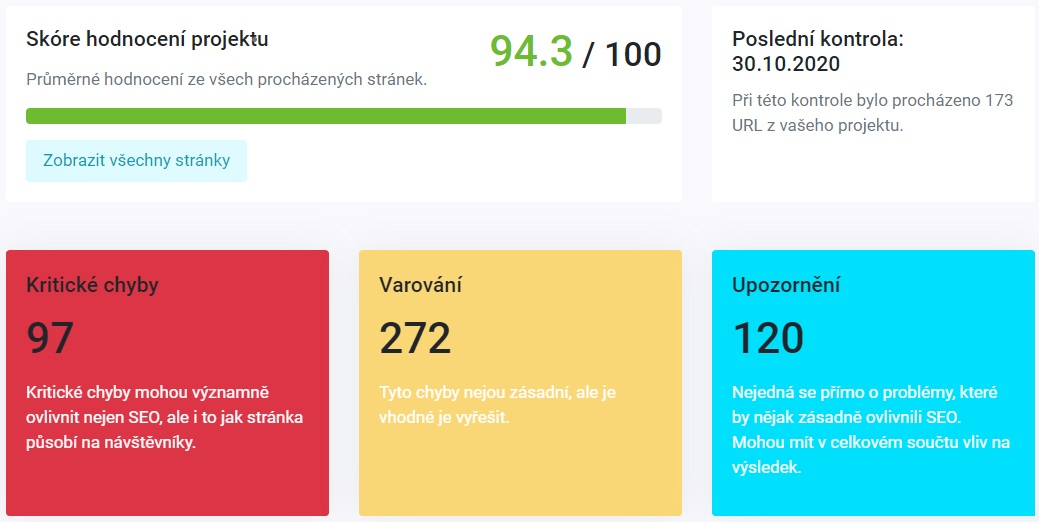
OnPage kontrola
Jednou za 3 dny náš robot projde až 200 stránek vašeho projektu a bude na nich kontrolovat duplicity nadpisů, meta popisků, chybové odkazy atd. Celkem máme připraveno 35 testů pro každou stránku, kterou náš robot navštíví.
Nejnovější recenze
Kontrola technického on-page SEO může být pro spoustu lidí nudnou rutinou, která se jim nechce dělat. Pokud ji však podcení a zanedbají, tak je to nakonec může stát víc než ztracený čas. Tady by se vyplatil nějaký nástroj. Jedním takovým je SEOwebmaster. V tomto článku se dozvíte, jak vám dokáže pomoci....https://www.webhostingcentrum.cz/seowebmaster-recenze/
Reference



